A few months back I was wondering how much big/difficult task it is to write a new programming language from scratch. Then I thought I would never know if I don’t write one by myself. Thats when I started reading about compilers, how it works and what are the phases involved in the code execution lifecycle.
Before that, a few months earlier I was learning theory of automata. Which contains a lot of concepts like DFA, NFA etc. And there were a lot of examples of identifying wether a string is matching using a DFA or not. Thats where the idea of identifying syntax using DFAs popped in my mind and I started on this new journey.
I know it was not going to be an easy task, thats why I read a lot of articles and watched a lot of youtube videos to understand the basics first. Now lets understand what are the basics steps involved in executing a code snippet and how I proceeded with them.
Before jumping into explanation, let me tell you I am writing this language called soft. Its not complete yet. Only the lexical analysis part is almost done. I just wanted share my learnings till now.
Before doing any of the below steps you have to decide syntax of your language, because only then you can perform scanning, parsing etc. The syntax/grammar of soft is this.
Things I have done till now..
Lexical Analyzer
In this phase of code compilation we take a stream of characters and convert them into meaningful tokes. Let’s understand by an example.
Code snippet
1
2
class Fruit
end
Now if I run lexical analysis on the above code snippet I would get
1
[KEY:class, ID:Fruit, KEY:end]
In the above tokens we have KEY for keyword and ID for Identifier, So the above tokens tells me what is what in the code. And from there I can take the things further. Keep the token an object because it will tell you a lot of other things as well like line number and character number of a token which is helpful when you print an error message or exception.
A lot of people use tools like yacc, lex to convert code snippet into tokens, but in my case I did not use any of the external tool to perform lexical analysis. Because it was all about learning and I wanted to do each and every phase on my own.
Following is the design of my Lexical analyzer
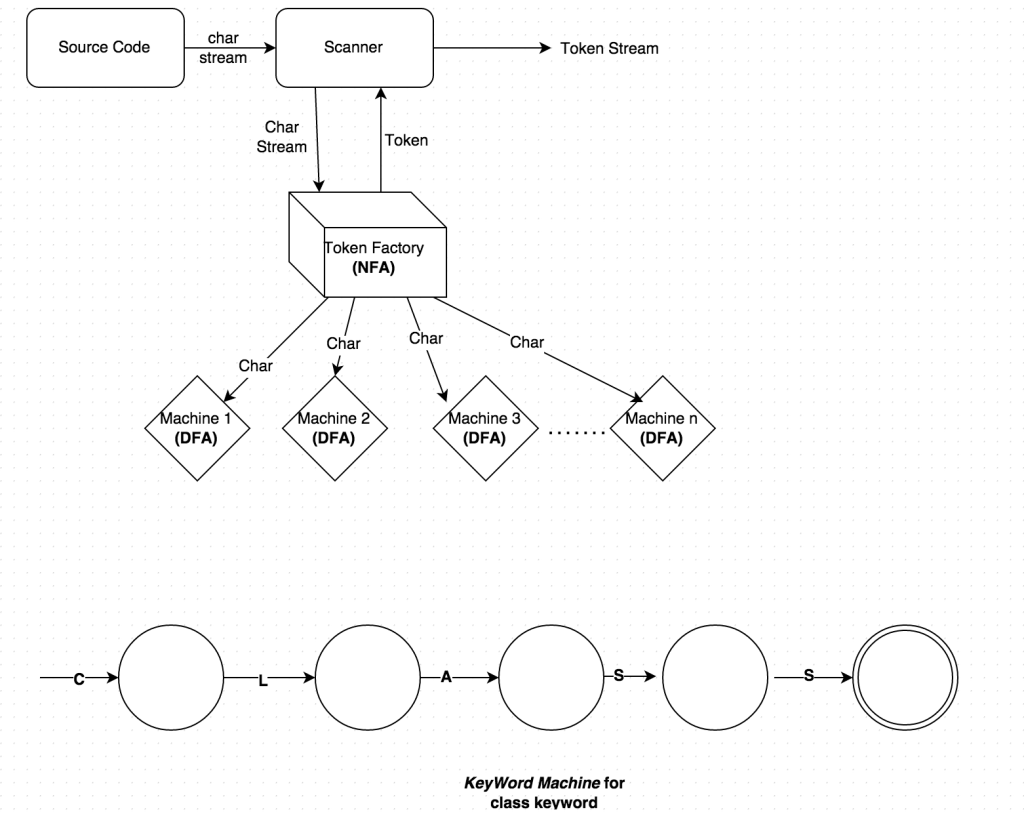
Scanner takes a stream of character from the source code and pass each character to the TokenFactory and then TokenFactory passes the char to all the machines(KeywordMachine, StringMachine etc.) that it has. Finally scanner asks for a token and the TokenFactory checks which machine is in final state and gets a token from that machine.
I am writing this language in ruby because I am not worried about performance or other stuff, I just want to learn things.
I did TDD during development so you can take a look at the test cases, And the most useful test here would be scanner specs. Some of the scanner tests are below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
require 'spec_helper'
describe :Scanner do
it 'should tokenize a while loop' do
source_code = <<-CODE
i = 10
while i > 0
print i
i = i - 1
end
CODE
tokens = Soft::Scanner.tokenize source_code
tokens.map! { |t| t.inspect }
tokens.should == %w(ID:i EQ EXP:10 KEY:while ID:i GT EXP:0 KEY:print ID:i ID:i EQ ID:i EXP:-1 KEY:end)
end
it 'should tokenize everything' do
source_code = <<-CODE
class HelloWorld
meth some_method_name
var_name = "Ajit Singh"
some_ex = 10+20*30
end
end
CODE
tokens = Soft::Scanner.tokenize source_code
tokens.map! { |t| t.inspect }
tokens.should == ['KEY:class', 'ID:HelloWorld',
'KEY:meth', 'ID:some_method_name',
'ID:var_name', 'EQ', 'STRING:Ajit Singh',
'ID:some_ex', 'EQ', 'EXP:10+20*30',
'KEY:end',
'KEY:end']
end
end
ISoft
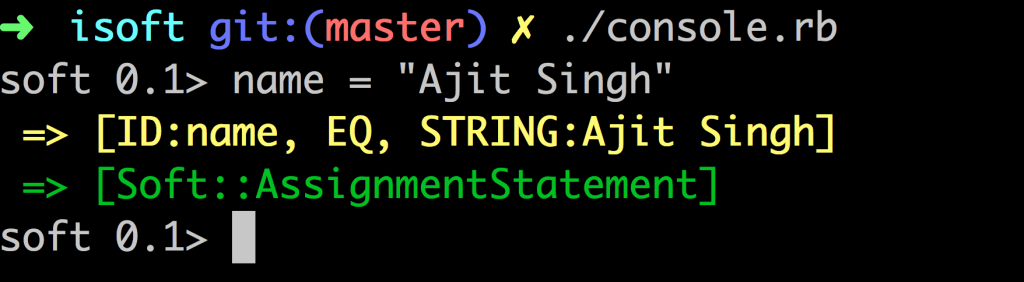
I also created an interactive shell that takes the code snippet and converts it into tokens (very basic stuff). You can see the code here. Below is the screen shot of the iSoft shell.
Thats all folks, I will keep you updated whenever I will start working on it again..