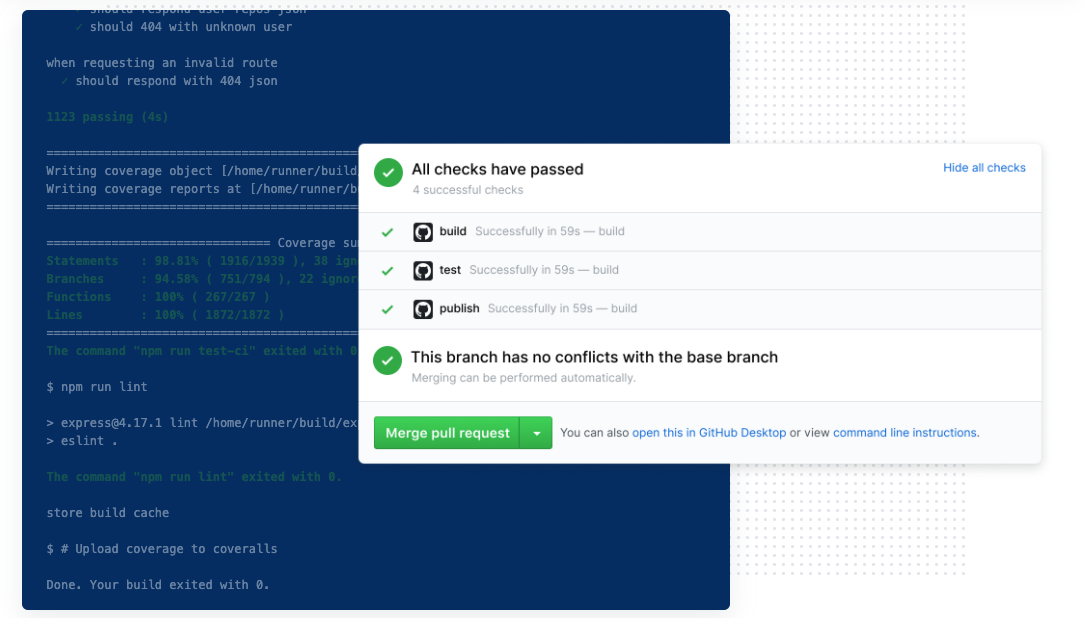
Use GitLab’s REST APIs to fetch failed job logs programmatically, then feed them to GPT with a structured prompt to categorize failures by type (network, dependency, config). This automated analysis can reveal patterns like ‘40% of failures stem from external dependencies’ and help prioritize fixes.
Imagine this: It’s 9 AM, your nightly scheduled CI/CD pipeline has failed again, and you’re scrolling through endless log files, hunting for that one elusive error message. Sound familiar? In my last assignment, this was our almost daily nightmare. With hundreds of pipelines running weekly, manual debugging was sucking the life out of our productivity. We needed a smarter way to uncover patterns in the chaos—something that could spotlight the root causes and help us fix them fast.
That’s when I rolled up my sleeves and built a pipeline autopsy tool using GitLab APIs to fetch failed job data and OpenAI’s GPT to dissect the logs. The result? A crystal-clear table categorizing failures, revealing that 40% of our issues stemmed from external dependencies and environmental issues. This insight let us prioritize fixes, slashing failure rates by 80%. If you’re battling unstable pipelines, stick around—I’ll walk you through the story, the tech, and how you can replicate it.
The Pipeline Predicament: A Tale of Endless Failurer
Our project was a beast: A large-scale microservices app with GitLab CI/CD pipelines handling everything from unit tests to deployments. But failures were rampant—network timeouts, dependency errors, environmental issues, config mishaps—you name it. Manually reviewing each failed job? That meant clicking into GitLab, digging through job logs, and jotting notes. For thousands of failures? Forget it; we’d need a team just for that.
The breaking point came during a sprint where our deployment got stuck for almost a week. We had to ask: What’s really breaking most often? Enter automation: GitLab’s powerful APIs for data extraction, paired with GPT’s natural language prowess for analysis. This combo turned weeks of manual work into a script that runs in minutes.
Step 1: Harvesting the Data with GitLab APIs
First things first: We needed to pull failed job details without lifting a finger. GitLab’s REST APIs are a goldmine for this. With a personal access token (grab one from your GitLab settings), you can query projects, pipelines, jobs, and even download raw logs.
Here’s how I did it in NodeJS using axios: just pasting enough code to give an idea how you can utlize Gitlab APIs. Do write a comment if you want the complete script.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
async function fetchPipelineJobs(pipelineId) {
try {
const response = await axios.get(`${GITLAB_API_BASE_URL}/projects/${PROJECT_ID}/pipelines/${pipelineId}/jobs`, {
headers: { 'PRIVATE-TOKEN': GITLAB_TOKEN }
});
return response.data;
} catch (error) {
console.error(`Error fetching jobs for pipeline ID ${pipelineId}:`, error.message);
return [];
}
}
async function fetchJobLogs(jobId) {
try {
const response = await axios.get(`${GITLAB_API_BASE_URL}/projects/${PROJECT_ID}/jobs/${jobId}/trace`, {
headers: { 'PRIVATE-TOKEN': GITLAB_TOKEN }
});
return response.data;
} catch (error) {
console.error(`Error fetching logs for job ID ${jobId}:`, error.message);
return null;
}
}
function generateTable(failedJobData) {
let csvContent = 'Pipeline URL,Stage,Job Name,Job URL,Failure Date,Log Location\n';
failedJobData.forEach(row => {
const csvRow = `"${row.pipelineUrl}","${row.stage}","${row.jobName}","${row.jobUrl}","${row.failureDate}","${row.logLocation || 'N/A'}"`;
csvContent += csvRow + '\n';
});
const date = new Date().toISOString().split('T')[0];
const csvFileName = `failed_jobs_analysis_${date}.csv`;
const csvFilePath = path.join(logsDir, csvFileName);
fs.writeFileSync(csvFilePath, csvContent, 'utf8');
console.log(`\nAnalysis table saved to: ${csvFilePath}`);
}
Step 2: Analyze failed job logs, Enters GPT!
With logs in hand, the real magic happened: Feeding them to GPT for analysis. OpenAI’s API (I used GPT-4o for its accuracy) can summarize errors, categorize failures, and even suggest fixes. The key? Craft precise prompts to extract structured output.
I batched logs (to stay under token limits) and prompted GPT to analyze each one, outputting in CSV format for easy table generation. Here’s an example prompt I used with the openai npm package (npm install openai):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const response = await openai.chat.completions.create({
model: model,
messages: [
{
role: "system",
content: "You are an expert DevOps engineer specializing in analyzing CI/CD job failures. Focus on identifying the ROOT CAUSE and the specific service/component that caused the failure. Respond in JSON format only"
},
{
role: "user",
content: "
You are an expert CI/CD pipeline analyst. Analyze this failed job log and extract:
- Brief summary: One sentence describing the main failure reason.
- Detailed summary: 2-3 sentences with key error details.
- Failure category: One of [Network Error, Dependency Issue, Test Failure, Configuration Error, Resource Limit, Unknown].
job_logs: ${job_logs}
"
}
],
temperature: 0.1
});
This prompt ensures GPT provides concise, categorized insights. For instance, if the log shows a timeout, it might return: { "brief_summary": "Network timeout during dependency fetch.", "detailed_summary": "The job failed due to a connection timeout while downloading packages from the registry. This occurred after 30 seconds, leading to incomplete dependencies.", "failure_category": "Network Error" }.
The Payoff: From Chaos to Control
What started as a frustration-fueled hack turned into a pipeline superpower. By automating failure analysis, we not only saved hours but also made data-driven decisions that boosted our overall stability. Failure rates dropped, deployments sped up, and the team could focus on building features instead of firefighting.
If your pipelines are a mess, give this a shot—adapt the scripts to your setup, tweak the prompts, and watch the insights roll in. Got questions or your own war stories? Drop a comment below. Let’s make CI/CD suck less, one API call at a time!
#SoftwareDevelopment #DevOps #GitLab #AI #CICD #PipelineOptimization #OpenAI #TechTutorials